Two Offprints on the Structure of Insulin; La Structure de l’Insuline [and] The Disulphide Bonds of Insulin



- SIGNED
- 1955
1955. First Edition. Sanger received the Nobel Prize in Chemistry in 1958 for determining the complete amino acid sequence of insulin (the first protein ever to have its primary structure fully established) and a second in 1980 for developing methods for sequencing DNA, making him one of only four individuals ever to have received two Nobel Prizes. The two offprints offered here, both signed by Sanger, together constitute the complete published record of that first achievement: a synthetic lecture delivered in Marseille in December 1954 presenting the full sequential strategy by which insulin’s structure was approached, and the definitive experimental paper establishing the positions of its three disulphide bridges—the final structural question the sequence work had left open. In demonstrating that a protein possesses a unique, fully definable covalent sequence, Sanger established the conceptual and methodological foundation upon which all subsequent structural biology rests. The principle that biological function is encoded in a specific primary sequence underlies every protein sequenced since, every therapeutic protein produced by recombinant technology, and every drug designed to interact with a defined molecular target; and the sequential degradation strategy Sanger developed for insulin was the direct intellectual precursor of the DNA sequencing methodology for which he received his second Nobel Prize; and which in turn made the Human Genome Project possible. (1) La Structure de l'Insuline; from Bulletin de la Société de Chimie biologique, Tome XXXVII, no. 1, pp.23–35. Paris: Masson et Cie, 1955. Offprint, 8vo (242 x 159mm), pp. 13, [3]. Original blue printed wrappers, staple-bound, some toning and rubbing, else near fine. Signed by Sanger on the front wrapper.
A lecture delivered on 13 December 1954 in Marseille, in which Sanger presents a synthetic account of the decade-long experimental program at the Department of Biochemistry, University of Cambridge, that resulted in the complete elucidation of the amino acid sequence of insulin; the first protein ever to have its primary structure fully determined. Setting aside earlier disputed molecular weight values in favor of a minimum covalent unit of 6,000 (later calculated at 5,734), Sanger describes the sequential strategy by which the complete structure was approached: first, the identification of two N-terminal residues (DNP-glycine and DNP-phenylalanine, one equivalent of each) using the fluorodinitrobenzene reagent he had himself introduced in 1945, establishing that insulin comprises two distinct polypeptide chains; then the separation of those chains by performic acid oxidation, which cleaved the cystine disulfide bridges and resolved the molecule into a glycyl chain A of approximately 20 residues and a phenylalanyl chain B of approximately 30; then the stepwise determination of the N-terminal sequences of both chains by partial hydrolysis and partition chromatography, establishing that chain B begins Phe.Val.Asp.Glu and chain A begins Gly.Ileu.Val.Glu.Glu; and finally the mapping of the disulfide bridge positions, including an intrachain ring at positions A6 and A11 whose dimensions Sanger notes are shared by oxytocin and vasopressin, and the two interchain bridges connecting A and B, determined through systematic chymotryptic and peptic hydrolysis under conditions preventing disulfide exchange. The significance of the work extends far beyond insulin: in demonstrating that a protein possesses a unique, fully definable covalent sequence, Sanger established the conceptual and methodological foundation upon which all subsequent structural biology rests, and the principle that biological function is encoded in a specific primary sequence underlies every protein sequenced since, every therapeutic protein produced by recombinant technology, and every drug designed to interact with a defined molecular target. Sanger received the Nobel Prize in Chemistry in 1958 for this work, and a second in 1980 for DNA sequencing, making him one of only four individuals ever to have received two Nobel Prizes.
(2) The Disulphide Bonds of Insulin; from The Biochemical Journal, Vol. 60, No. 4, pp. 541–556. London: Portland Press, 1955. Offprint, 8vo (254 x 185mm), pp. 16. String-bound self-wrappers, soft creases, a few scattered spots of soiling, near fine. Signed by Sanger on the front wrapper.
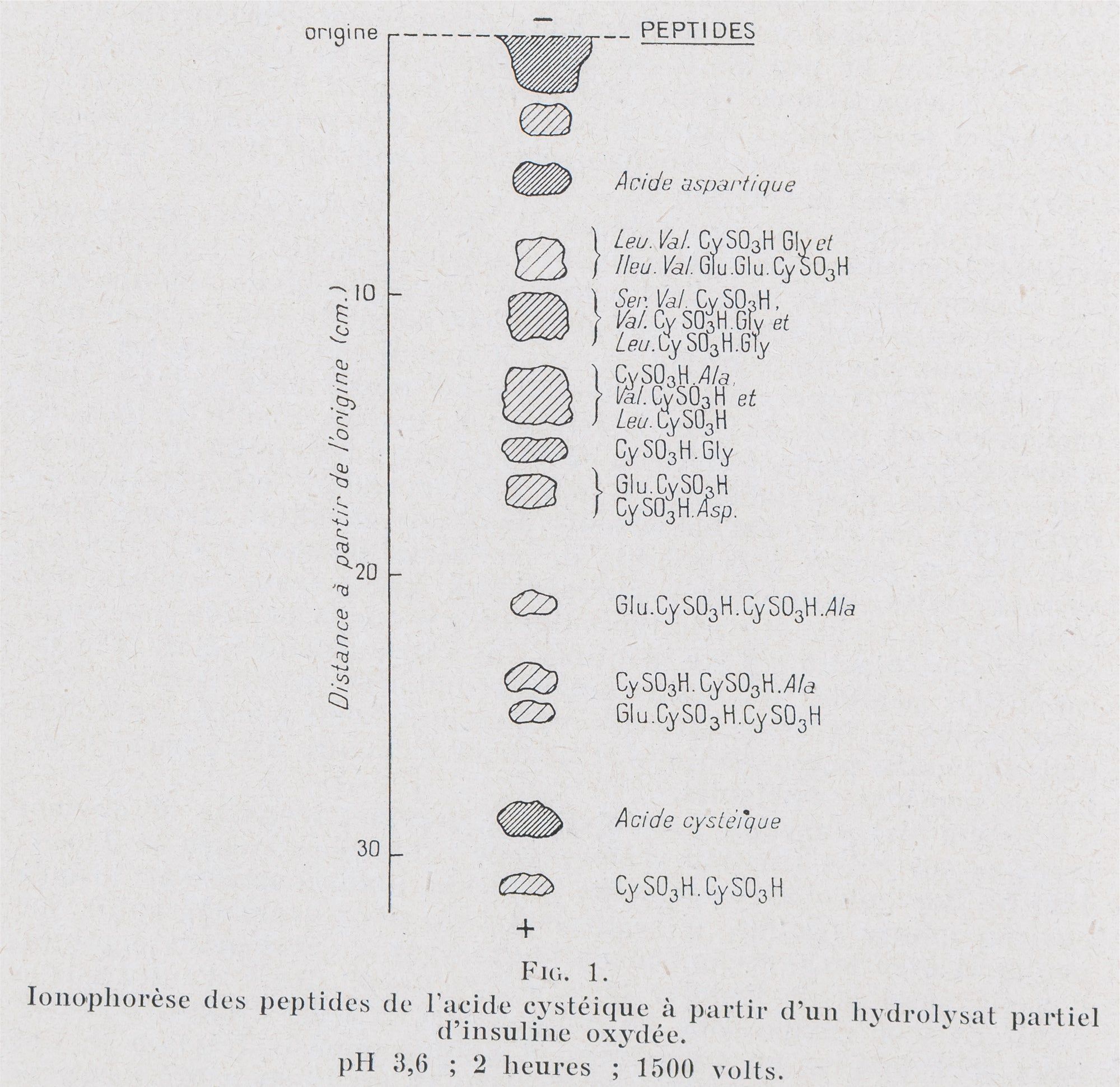
Received 26 November 1954 at the Department of Biochemistry, University of Cambridge, this paper by Ryle, Sanger, Smith, and Kitai addresses the final structural question left open by the sequence determinations of the preceding years: the positions of the three disulphide bridges linking its six half-cystine residues. The paper begins by establishing the molecular weight of insulin as 5,734, calculated from the condensation of its constituent amino acids, and confirms that the molecule comprises two polypeptide chains (the glycyl chain A and the phenylalanyl chain B) joined by the disulphide bridges of three cystine residues, with fraction A containing four cysteic acid residues and fraction B two on oxidation. The experimental strategy proceeds in five defined stages: partial hydrolysis of insulin under conditions in which the disulphide bonds remained intact; fractionation of the resulting cystine-containing peptides; oxidation of those peptides to the corresponding cysteic acid peptides; fractionation of the cysteic acid peptides; and identification of their structures from the amino acids produced on hydrolysis. The central technical difficulty throughout was the prevention of disulphide interchange, which occurred readily under neutral conditions catalysed by thiol compounds and could be inhibited by N-ethylmaleimide (NEMI), and more slowly under acid conditions, particularly in H SO rather than HCl. The primary separation method was high-voltage paper ionophoresis in pyridine-acetic acid buffers, which the authors found more reliable than paper chromatography for resolving cystine-containing peptides, supplemented by ion-exchange chromatography on Amberlite IR-4B and two-dimensional ionophoresis. Hydrolysis was carried out with chymotrypsin, with a crude pancreatic extract, and with acid, each providing complementary peptide populations; no enzyme could be found capable of cleaving between the half-cystine residues at positions A6 and A7, so acid hydrolysis was required to locate the remaining two disulphide bridges. The results, summarized in Table 10, establish the complete disulphide connectivity of insulin: an intrachain ring connecting positions A6 and A11 of the glycyl chain — a ring of the same size as those found in oxytocin and vasopressin, a structural parallel the authors note may have possible structural or biological significance — and two interchain bridges connecting A20 to B19 and A7 to B7. This paper completes the structural determination of insulin begun in Sanger's earlier sequence work, and together they constitute the first complete covalent structure of any protein — a landmark from which the entire subsequent program of structural molecular biology and rational protein-based drug design descends.
A lecture delivered on 13 December 1954 in Marseille, in which Sanger presents a synthetic account of the decade-long experimental program at the Department of Biochemistry, University of Cambridge, that resulted in the complete elucidation of the amino acid sequence of insulin; the first protein ever to have its primary structure fully determined. Setting aside earlier disputed molecular weight values in favor of a minimum covalent unit of 6,000 (later calculated at 5,734), Sanger describes the sequential strategy by which the complete structure was approached: first, the identification of two N-terminal residues (DNP-glycine and DNP-phenylalanine, one equivalent of each) using the fluorodinitrobenzene reagent he had himself introduced in 1945, establishing that insulin comprises two distinct polypeptide chains; then the separation of those chains by performic acid oxidation, which cleaved the cystine disulfide bridges and resolved the molecule into a glycyl chain A of approximately 20 residues and a phenylalanyl chain B of approximately 30; then the stepwise determination of the N-terminal sequences of both chains by partial hydrolysis and partition chromatography, establishing that chain B begins Phe.Val.Asp.Glu and chain A begins Gly.Ileu.Val.Glu.Glu; and finally the mapping of the disulfide bridge positions, including an intrachain ring at positions A6 and A11 whose dimensions Sanger notes are shared by oxytocin and vasopressin, and the two interchain bridges connecting A and B, determined through systematic chymotryptic and peptic hydrolysis under conditions preventing disulfide exchange. The significance of the work extends far beyond insulin: in demonstrating that a protein possesses a unique, fully definable covalent sequence, Sanger established the conceptual and methodological foundation upon which all subsequent structural biology rests, and the principle that biological function is encoded in a specific primary sequence underlies every protein sequenced since, every therapeutic protein produced by recombinant technology, and every drug designed to interact with a defined molecular target. Sanger received the Nobel Prize in Chemistry in 1958 for this work, and a second in 1980 for DNA sequencing, making him one of only four individuals ever to have received two Nobel Prizes.
(2) The Disulphide Bonds of Insulin; from The Biochemical Journal, Vol. 60, No. 4, pp. 541–556. London: Portland Press, 1955. Offprint, 8vo (254 x 185mm), pp. 16. String-bound self-wrappers, soft creases, a few scattered spots of soiling, near fine. Signed by Sanger on the front wrapper.
Received 26 November 1954 at the Department of Biochemistry, University of Cambridge, this paper by Ryle, Sanger, Smith, and Kitai addresses the final structural question left open by the sequence determinations of the preceding years: the positions of the three disulphide bridges linking its six half-cystine residues. The paper begins by establishing the molecular weight of insulin as 5,734, calculated from the condensation of its constituent amino acids, and confirms that the molecule comprises two polypeptide chains (the glycyl chain A and the phenylalanyl chain B) joined by the disulphide bridges of three cystine residues, with fraction A containing four cysteic acid residues and fraction B two on oxidation. The experimental strategy proceeds in five defined stages: partial hydrolysis of insulin under conditions in which the disulphide bonds remained intact; fractionation of the resulting cystine-containing peptides; oxidation of those peptides to the corresponding cysteic acid peptides; fractionation of the cysteic acid peptides; and identification of their structures from the amino acids produced on hydrolysis. The central technical difficulty throughout was the prevention of disulphide interchange, which occurred readily under neutral conditions catalysed by thiol compounds and could be inhibited by N-ethylmaleimide (NEMI), and more slowly under acid conditions, particularly in H SO rather than HCl. The primary separation method was high-voltage paper ionophoresis in pyridine-acetic acid buffers, which the authors found more reliable than paper chromatography for resolving cystine-containing peptides, supplemented by ion-exchange chromatography on Amberlite IR-4B and two-dimensional ionophoresis. Hydrolysis was carried out with chymotrypsin, with a crude pancreatic extract, and with acid, each providing complementary peptide populations; no enzyme could be found capable of cleaving between the half-cystine residues at positions A6 and A7, so acid hydrolysis was required to locate the remaining two disulphide bridges. The results, summarized in Table 10, establish the complete disulphide connectivity of insulin: an intrachain ring connecting positions A6 and A11 of the glycyl chain — a ring of the same size as those found in oxytocin and vasopressin, a structural parallel the authors note may have possible structural or biological significance — and two interchain bridges connecting A20 to B19 and A7 to B7. This paper completes the structural determination of insulin begun in Sanger's earlier sequence work, and together they constitute the first complete covalent structure of any protein — a landmark from which the entire subsequent program of structural molecular biology and rational protein-based drug design descends.
Details
Title
Two Offprints on the Structure of Insulin; La Structure de l’Insuline [and] The Disulphide Bonds of Insulin
Author
Sanger, Frederick
Condition
Unknown
Date
1955
Edition
First Edition